PostgreSQL
# Jupyter require additional python modules in order to make sql magick working...
#> pip install "pgspecial<2" -q
#> pip install ipython-sql pgspecial psycopg2 -q
Northwind db can be downloaded here or anywhere else… its northwind after all…
#> curl -s https://gist.githubusercontent.com/butuzov/ef20f47c020ecdbbde19090fbd9e8fc7/raw/74983701f1ead70f053e7590e754b7528e4aaa27/northwind.sql --output _tmp_northwind2.sql
#> docker-compose up -d
> �[1A�[1B�[0G�[?25l[+] Running 1/0
> �[32m✔�[0m Container postgres-postgresql-1 �[32mR...�[0m �[34m0.0s �[0m
> �[?25h
postgresql://postgres:postgres@localhost:5432/northwind
#psql
docker exec -it postgres-postgresql-1 psql -U postgres -h localhost -d northwind
WARNING:
Not all commands are supported via jupyter / pgspecial
| Schema |
Name |
Type |
Owner |
| public |
categories |
table |
postgres |
| public |
customer_customer_demo |
table |
postgres |
| public |
customer_demographics |
table |
postgres |
| public |
customers |
table |
postgres |
| public |
employee_territories |
table |
postgres |
| public |
employees |
table |
postgres |
| public |
order_details |
table |
postgres |
| public |
orders |
table |
postgres |
| public |
products |
table |
postgres |
| public |
region |
table |
postgres |
| public |
shippers |
table |
postgres |
| public |
suppliers |
table |
postgres |
| public |
territories |
table |
postgres |
| public |
us_states |
table |
postgres |
Some other examples of psql
\t - tuples only\a - no extra breaking elements (added by psql)\q query.sql - rediect to sql.\o stop redirection.\i query.sql - execute generated script\du - users- etc…
#psql Customizations
\pset null 'NULL'
\encoding latin1
\set PROMPT1 '%n@%M:%>%x %/# '
\pset pager always
\timing on
\set qstats92 '
SELECT usename, datname, left(query,100) || ''...'' as query
FROM pg_stat_activity WHERE state != ''idle'' ;
\timing setting timing for queryies on\set AUTOCOMMIT off
#Describe & List
| Schema |
Name |
Type |
Owner |
| public |
categories |
table |
postgres |
| public |
customer_customer_demo |
table |
postgres |
| public |
customer_demographics |
table |
postgres |
| public |
customers |
table |
postgres |
| public |
employee_territories |
table |
postgres |
| public |
employees |
table |
postgres |
| public |
order_details |
table |
postgres |
| public |
orders |
table |
postgres |
| public |
products |
table |
postgres |
| public |
region |
table |
postgres |
| public |
shippers |
table |
postgres |
| public |
suppliers |
table |
postgres |
| public |
territories |
table |
postgres |
| public |
us_states |
table |
postgres |
\dt pg_catalog.pg_t*
> 9 rows affected.
| Schema |
Name |
Type |
Owner |
| pg_catalog |
pg_tablespace |
table |
postgres |
| pg_catalog |
pg_transform |
table |
postgres |
| pg_catalog |
pg_trigger |
table |
postgres |
| pg_catalog |
pg_ts_config |
table |
postgres |
| pg_catalog |
pg_ts_config_map |
table |
postgres |
| pg_catalog |
pg_ts_dict |
table |
postgres |
| pg_catalog |
pg_ts_parser |
table |
postgres |
| pg_catalog |
pg_ts_template |
table |
postgres |
| pg_catalog |
pg_type |
table |
postgres |
# db list
\l
> 4 rows affected.
| Name |
Owner |
Encoding |
Collate |
Ctype |
Access privileges |
| northwind |
postgres |
UTF8 |
en_US.utf8 |
en_US.utf8 |
None |
| postgres |
postgres |
UTF8 |
en_US.utf8 |
en_US.utf8 |
None |
| template0 |
postgres |
UTF8 |
en_US.utf8 |
en_US.utf8 |
=c/postgres
postgres=CTc/postgres |
| template1 |
postgres |
UTF8 |
en_US.utf8 |
en_US.utf8 |
=c/postgres
postgres=CTc/postgres |
| Schema |
Name |
Type |
Owner |
Size |
Description |
| public |
categories |
table |
postgres |
16 kB |
None |
| public |
customer_customer_demo |
table |
postgres |
8192 bytes |
None |
| public |
customer_demographics |
table |
postgres |
8192 bytes |
None |
| public |
customers |
table |
postgres |
48 kB |
None |
| public |
employee_territories |
table |
postgres |
8192 bytes |
None |
| public |
employees |
table |
postgres |
16 kB |
None |
| public |
order_details |
table |
postgres |
120 kB |
None |
| public |
orders |
table |
postgres |
144 kB |
None |
| public |
products |
table |
postgres |
8192 bytes |
None |
| public |
region |
table |
postgres |
16 kB |
None |
| public |
shippers |
table |
postgres |
8192 bytes |
None |
| public |
suppliers |
table |
postgres |
16 kB |
None |
| public |
territories |
table |
postgres |
16 kB |
None |
| public |
us_states |
table |
postgres |
8192 bytes |
None |
#Connect
\c pg_catalog - coonect ot db
#Import & export
copy table_name FROM file.txt DELIMITER '|';copy table_name FROM file.csv;copy table_name FROM file.csv NULL as '';
\copy (SELECT * FROM staging.factfinder_import WHERE s01 ~ E'^[0-9]+' )
TO '/test.tab'
WITH DELIMITER E'\t' CSV HEADER
-- double quote all columns
\copy staging.factfinder_import TO '/test.csv'
WITH CSV HEADER QUOTE '"' FORCE QUOTE *
Export as html with -H option.
#Data Types
#Numerics
#Serials / Sequences
DROP SEQUENCE IF EXISTS s;
CREATE SEQUENCE s START 1;
DROP TABLE IF EXISTS stuff ;
CREATE TABLE stuff(
id bigint DEFAULT nextval('s') PRIMARY KEY, name text);
> Done.
> Done.
> Done.
> Done.
result >>> []
SELECT nextval('s')
> 1 rows affected.
SELECT x FROM generate_series(1,51,20) as x;
> 3 rows affected.
#Textual
#String Functions
SELECT
lpad('ab', 4, '0') as ab_lpad,
rpad('ab', 4, '0') as ab_rpad,
lpad('abcde', 4, '0') as ab_lpad_trunc;
> 1 rows affected.
| ab_lpad |
ab_rpad |
ab_lpad_trunc |
| 00ab |
ab00 |
abcd |
SELECT
-- different trim types
a as a_before,
trim(a) as a_trim,
rtrim(a) as a_rt,
i as i_before,
ltrim(i, '0') as i_lt_0,
rtrim(i, '0') as i_rt_0,
trim(i, '0') as i_t_0
FROM (
-- concat with padding 4 spacing a number...
SELECT
repeat(' ', 4) || i || repeat(' ', 4) as a,
'0' || i as i
FROM generate_series(0, 200, 50) as i
) as x;
> 5 rows affected.
| a_before |
a_trim |
a_rt |
i_before |
i_lt_0 |
i_rt_0 |
i_t_0 |
| 0 |
0 |
0 |
00 |
|
|
|
| 50 |
50 |
50 |
050 |
50 |
05 |
5 |
| 100 |
100 |
100 |
0100 |
100 |
01 |
1 |
| 150 |
150 |
150 |
0150 |
150 |
015 |
15 |
| 200 |
200 |
200 |
0200 |
200 |
02 |
2 |
SELECT split_part('abc.123.z45','.',2) as x;
> 1 rows affected.
SELECT unnest(string_to_array('abc.123.z45', '.')) as x;
> 3 rows affected.
SELECT regexp_replace( '6197306254',
'([0-9]{3})([0-9]{3})([0-9]{4})',
E'\(\\1\) \\2-\\3'
) as x;
> 1 rows affected.
SELECT unnest(
regexp_matches(
'Cell (619) 852-5083. Work (619)123-4567 , Casa 619-730-6254. Bésame mucho.',
E'[(]{0,1}[0-9]{3}[)-.]{0,1}[\\s]{0,1}[0-9]{3}[-.]{0,1}[0-9]{4}', 'g')
) as x
> 0 rows affected.
SELECT substring(
'Cell (619) 852-5083. Work (619)123-4567 , Casa 619-730-6254. Bésame mucho.'
FROM E'[(]{0,1}[0-9]{3}[)-.]{0,1}[\\s]{0,1}[0-9]{3}[-.]{0,1}[0-9]{4}'
) as x;
> 1 rows affected.
#Temporal Data
date - Stores the month, day, and year, with no time zone awareness and no concept of hours, minutes, or seconds.time (aka time without time zone): Stores hours, minutes, and seconds with no awareness of time zone or calendar dates.timestamp (aka timestamp without time zone): Stores both calendar dates and time (hours, minutes, seconds) but does not care about the time zone.timestamptz (aka timestamp with time zone): A time zone−aware date and time data type. Internally, timestamptz is stored in Coordinated Universal Time (UTC), but its display defaults to the time zone of the server, the service config, the database, the user, or the session. Yes, you can observe different time zones at different levels. If you input a timestamp with no time zone and cast it to one with the time zone, PostgreSQL assumes the default time zone in effect. If you don’t set your time zone in postgresql.conf, the server’s default takes effect. This means that if you change your server’s time zone, you’ll see all the displayed times change after the PostgreSQL restarts.timetz (aka time with time zone): The lesser-used sister of timestamptz. It is time zone−aware but does not store the date. It always assumes DST of the current date and time. Some programming languages with no concept of time without date might map timetz to a timestamp with some arbitrary date such as Unix Epoch 1970, resulting in year 1970 being assumed.interval: A duration of time in hours, days, months, minutes, and others. It comes in handy for datetime arithmetic. For example, if the world is supposed to end in exactly 666 days from now, all you have to do is add an interval of 666 days to the current time to get the exact moment (and plan accordingly).tsrange: Allows you to define opened and closed ranges of timestamp with no timezone. The type consists of two timestamps and opened/closed range qualifiers. For example, '[2012-01-01 14:00, 2012-01-01 15:00)'::tsrange defines a period starting at 14:00 but ending before 15:00. Refer to Range Types for details.tstzrange: Allows you to define opened and closed ranges of timestamp with timezone.daterange: Allows you to define opened and closed ranges of dates.
SELECT '2012-03-11 3:10 AM America/Los_Angeles'::timestamptz
- '2012-03-11 1:50 AM America/Los_Angeles'::timestamptz;
> 1 rows affected.
SELECT '2012-03-11 3:10 AM'::timestamp - '2012-03-11 1:50 AM'::timestamp;
> 1 rows affected.
SELECT '2012-02-28 10:00 PM America/Los_Angeles'::timestamptz
> 1 rows affected.
| timestamptz |
| 2012-02-29 06:00:00+00:00 |
SELECT '2012-02-28 10:00 PM America/Los_Angeles'::timestamptz AT TIME ZONE 'Europe/Paris';
> 1 rows affected.
| timezone |
| 2012-02-29 07:00:00 |
SELECT '2012-02-10 11:00 PM'::timestamp + interval '1 hour'
> 1 rows affected.
| ?column? |
| 2012-02-11 00:00:00 |
SELECT '23 hours 20 minutes'::interval + '1 hour'::interval;
> 1 rows affected.
SELECT '2012-02-10 11:00 PM'::timestamptz - interval '1 hour';
> 1 rows affected.
| ?column? |
| 2012-02-10 22:00:00+00:00 |
SELECT
('2012-10-25 10:00 AM'::timestamp, '2012-10-25 2:00 PM'::timestamp)
OVERLAPS
('2012-10-25 11:00 AM'::timestamp,'2012-10-26 2:00 PM'::timestamp) as x,
--- other variation
('2012-10-25'::date,'2012-10-26'::date)
OVERLAPS
('2012-10-26'::date,'2012-10-27'::date) as y;
> 1 rows affected.
SELECT (dt - interval '1 day')::date as eom
FROM generate_series('2/1/2012', '4/30/2012', interval '1 month') as dt;
> 3 rows affected.
| eom |
| 2012-01-31 |
| 2012-02-29 |
| 2012-03-31 |
SELECT dt,
date_part('hour', dt) as hr,
to_char(dt,'HH12:MI AM') as mn
FROM
generate_series(
'2012-03-11 12:30 AM',
'2012-03-11 1:20 AM',
interval '15 minutes'
) as dt;
> 4 rows affected.
| dt |
hr |
mn |
| 2012-03-11 00:30:00+00:00 |
0.0 |
12:30 AM |
| 2012-03-11 00:45:00+00:00 |
0.0 |
12:45 AM |
| 2012-03-11 01:00:00+00:00 |
1.0 |
01:00 AM |
| 2012-03-11 01:15:00+00:00 |
1.0 |
01:15 AM |
#Arrays
SELECT ARRAY[2001, 2002, 2003] as yrs;
> 1 rows affected.
SELECT string_to_array('CA.MA.TX', '.') as estados;
> 1 rows affected.
| estados |
| ['CA', 'MA', 'TX'] |
SELECT '{Alex,Sonia}'::text[] as name, '{46,43}'::smallint[] as age;
> 1 rows affected.
| name |
age |
| ['Alex', 'Sonia'] |
[46, 43] |
-- column to array
SELECT array_agg(data.region_description) as x
FROM
(SELECT * FROM region) as data;
> 1 rows affected.
| x |
| ['Eastern', 'Western', 'Northern', 'Southern'] |
-- select into arrray from values
SELECT array_agg(f.t)
FROM ( VALUES ('{Alex,Sonia}'::text[]), ('{46,43}'::text[] ) ) as f(t)
> 1 rows affected.
| array_agg |
| [['Alex', 'Sonia'], ['46', '43']] |
SELECT unnest('{XOX, OXO, XOX}'::char(3)[]) as tic_tac_toe;
> 3 rows affected.
SELECT
unnest( '{blind,mouse}'::varchar[]) as v,
unnest('{1,2,3}'::smallint[]) as i;
> 3 rows affected.
| v |
i |
| blind |
1 |
| mouse |
2 |
| None |
3 |
SELECT * FROM unnest('{blind,mouse}'::text[], '{1,2,3}'::int[]) as f(t,i);
> 3 rows affected.
| t |
i |
| blind |
1 |
| mouse |
2 |
| None |
3 |
#Array Slicing and Splicing
SELECT d.y[2:3] FROM (SELECT ARRAY[2001, 2002, 2003, 2004] as y ) as d
> 1 rows affected.
-- will fail in postgress>=14
-- SELECT '{1, 2, 3}'::integer[] || 4 || 5 as x;
SELECT ARRAY[1,2,3]::integer[] || 4 || 5 as x
> 1 rows affected.
SELECT
d.c[1] as primero,
d.c[array_upper(d.c, 1)] as segundo
FROM (SELECT ARRAY[0,1,2,3,4] as c ) as d
> 1 rows affected.
#Array Containment Checks
=, <>, <, >, @>, <@, and &&.
SELECT ARRAY[1,2,3]
> 1 rows affected.
-- contains - is all of 2,3 subset of the 1,2,3
SELECT ARRAY[1,2,3]::int[] @> ARRAY[3,2]::int[] as contains
> 1 rows affected.
-- contained - is all of 1,2,3 subset of the 2,3
SELECT ARRAY[1,2,3]::int[] <@ ARRAY[3,2]::int[] as contains
> 1 rows affected.
-- && any elements in common
SELECT
ARRAY[1,2,3]::int[] && ARRAY[3,2]::int[] as contains
> 1 rows affected.
#Range Types
int4range, int8range - A range of integers. Integer ranges are discrete and subject to canonicalization.numrange - A continuous range of decimals, floating-point numbers, or double-precision numbers.daterange - A discrete date range of calendar dates without time zone awareness.tsrange, tstzrange - A continuous date and time (timestamp) range allowing for fractional seconds. tstrange is not time zone−aware; tstzrange is time zone−aware.
SELECT '[2013-01-05,2013-08-13]'::daterange;
> 1 rows affected.
| daterange |
| [2013-01-05, 2013-08-14) |
SELECT '(0,)'::int8range;
> 1 rows affected.
SELECT '(2013-01-05 10:00,2013-08-13 14:00]'::tsrange;
> 1 rows affected.
| tsrange |
| (2013-01-05 10:00:00, 2013-08-13 14:00:00] |
SELECT daterange('2013-01-05','infinity','[]');
> 1 rows affected.
| daterange |
| [2013-01-05, 9999-12-31] |
#Tables
DROP TABLE IF EXISTS employment;
CREATE TABLE IF NOT EXISTS employment (
id serial PRIMARY KEY,
employee varchar(20),
period daterange);
CREATE INDEX ix_employment_period ON employment USING gist (period);
INSERT INTO employment (employee,period)
VALUES
('Alex','[2012-04-24, infinity)'::daterange),
('Sonia','[2011-04-24, 2012-06-01)'::daterange),
('Leo','[2012-06-20, 2013-04-20)'::daterange),
('Regina','[2012-06-20, 2013-04-20)'::daterange);
> Done.
> Done.
> Done.
> 4 rows affected.
result >>> []
#overlap operator
SELECT
e1.employee,
string_agg(DISTINCT e2.employee, ', ' ORDER BY e2.employee) as colleagues
FROM employment as e1
INNER JOIN employment as e2
-- first opverlats in perion with e2
ON e1.period && e2.period
-- excluding employee itself
WHERE e1.employee <> e2.employee
GROUP BY e1.employee;
> 4 rows affected.
| employee |
colleagues |
| Alex |
Leo, Regina, Sonia |
| Leo |
Alex, Regina |
| Regina |
Alex, Leo |
| Sonia |
Alex |
#contains Operator
SELECT employee FROM employment
WHERE period @> CURRENT_DATE
GROUP BY employee;
> 1 rows affected.
#JSON
DROP TABLE IF EXISTS persons;
CREATE TABLE persons (id serial PRIMARY KEY, person json);
INSERT INTO persons (person)
VALUES (
'{
"name":"Sonia",
"spouse":
{
"name":"Alex",
"parents":
{
"father":"Rafael",
"mother":"Ofelia"
},
"phones":
[
{
"type":"work",
"number":"619-722-6719"
},
{
"type":"cell",
"number":"619-852-5083"
}
]
},
"children":
[
{
"name":"Brandon",
"gender":"M"
},
{
"name":"Azaleah",
"girl": true,
"phones": []
}
]
}'
);
> Done.
> Done.
> 1 rows affected.
result >>> []
SELECT person->'name' FROM persons;
> 1 rows affected.
SELECT person->'spouse'->'parents'->'father' FROM persons;
> 1 rows affected.
SELECT person#>array['spouse','parents','father'] FROM persons;
> 1 rows affected.
SELECT person->'children'->0->'name' FROM persons;
> 1 rows affected.
SELECT person->'spouse'->'parents'->>'father' FROM persons
> 1 rows affected.
SELECT json_array_elements(person->'children')->>'name' as name FROM persons;
> 2 rows affected.
#Selecting JOSN
SELECT row_to_json(f) as x
FROM (
SELECT id, json_array_elements(person->'children')->>'name' as cname FROM persons
) as f;
> 2 rows affected.
| x |
| {'id': 1, 'cname': 'Brandon'} |
| {'id': 1, 'cname': 'Azaleah'} |
SELECT row_to_json(f) as jsoned_row FROM persons as f;
> 1 rows affected.
| jsoned_row |
| {'id': 1, 'person': {'name': 'Sonia', 'spouse': {'name': 'Alex', 'parents': {'father': 'Rafael', 'mother': 'Ofelia'}, 'phones': [{'type': 'work', 'number': '619-722-6719'}, {'type': 'cell', 'number': '619-852-5083'}]}, 'children': [{'name': 'Brandon', 'gender': 'M'}, {'name': 'Azaleah', 'girl': True, 'phones': []}]}} |
DROP TABLE IF EXISTS persons;
> Done.
result >>> []
#JSONB
CREATE TABLE IF NOT EXISTS persons_b (id serial PRIMARY KEY, person jsonb);
INSERT INTO persons_b (person)
VALUES (
'{
"name":"Sonia",
"spouse":
{
"name":"Alex",
"parents":
{
"father":"Rafael",
"mother":"Ofelia"
},
"phones":
[
{
"type":"work",
"number":"619-722-6719"
},
{
"type":"cell",
"number":"619-852-5083"
}
]
},
"children":
[
{
"name":"Brandon",
"gender":"M"
},
{
"name":"Azaleah",
"girl": true,
"phones": []
}
]
}'
);
> Done.
> 1 rows affected.
result >>> []
SELECT person as b FROM persons_b WHERE id = 1
> 1 rows affected.
| b |
| {'name': 'Sonia', 'spouse': {'name': 'Alex', 'phones': [{'type': 'work', 'number': '619-722-6719'}, {'type': 'cell', 'number': '619-852-5083'}], 'parents': {'father': 'Rafael', 'mother': 'Ofelia'}}, 'children': [{'name': 'Brandon', 'gender': 'M'}, {'girl': True, 'name': 'Azaleah', 'phones': []}]} |
SELECT person->>'name' as name
FROM persons_b
WHERE person @> '{"children":[{"name":"Brandon"}]}';
> 1 rows affected.
DROP INDEX IF EXISTS ix_persons_jb_person_gin;
CREATE INDEX ix_persons_jb_person_gin ON persons_b USING gin (person);
> Done.
> Done.
result >>> []
#Editing JSONB data
-- Concatenation
UPDATE persons_b
SET person = person || '{"address": "Somewhere in San Diego, CA"}'::jsonb
WHERE person @> '{"name":"Sonia"}'
RETURNING person
> 1 rows affected.
| person |
| {'name': 'Sonia', 'spouse': {'name': 'Alex', 'phones': [{'type': 'work', 'number': '619-722-6719'}, {'type': 'cell', 'number': '619-852-5083'}], 'parents': {'father': 'Rafael', 'mother': 'Ofelia'}}, 'address': 'Somewhere in San Diego, CA', 'children': [{'name': 'Brandon', 'gender': 'M'}, {'girl': True, 'name': 'Azaleah', 'phones': []}]} |
-- drop adress from rows where name is sonia
UPDATE persons_b
SET person = person - 'address'
WHERE person @> '{"name":"Sonia"}';
> 1 rows affected.
result >>> []
UPDATE persons_b
-- path denotion, update will work for second child of sonia, girsl wil be removed
SET person = person #- '{children,1,girl}'::text[]
WHERE person @> '{"name":"Sonia"}'
RETURNING person->'children'->1;
> 1 rows affected.
| ?column? |
| {'name': 'Azaleah', 'phones': []} |
UPDATE persons_b
SET
person = jsonb_set(person,'{children,1,gender}'::text[],'"F"'::jsonb, true)
WHERE person @> '{"name":"Sonia"}'
RETURNING person
> 1 rows affected.
| person |
| {'name': 'Sonia', 'spouse': {'name': 'Alex', 'phones': [{'type': 'work', 'number': '619-722-6719'}, {'type': 'cell', 'number': '619-852-5083'}], 'parents': {'father': 'Rafael', 'mother': 'Ofelia'}}, 'children': [{'name': 'Brandon', 'gender': 'M'}, {'name': 'Azaleah', 'gender': 'F', 'phones': []}]} |
#TODO XML
#TSVector
SELECT 'When a good man goes to war'::tsvector @@ 'good & war'::tsquery as Result
> 1 rows affected.
SELECT 'When a good man goes to war'::tsvector @@ to_tsquery('good & war') as Result
> 1 rows affected.
SELECT 'When a good man goes to war'::tsvector @@ 'good & war'::tsquery as Result
> 1 rows affected.
Search adjacent string combination
SELECT to_tsvector('When a good man goes to war') @@ to_tsquery('good <-> man') as Result
> 1 rows affected.
SELECT 'When a good man goes to war'::tsvector @@ to_tsquery('good <-> man') as Result
> 1 rows affected.
SELECT to_tsvector('When a good man goes to war') @@ to_tsquery('good <2> goes') as Result
> 1 rows affected.
#TSQueries
SELECT to_tsvector('good man goes') @@ to_tsquery('good <2> patel') as Result
> 1 rows affected.
SELECT to_tsquery('business & analytics');
> 1 rows affected.
| to_tsquery |
| 'busi' & 'analyt' |
SELECT to_tsquery('english','business & analytics');
> 1 rows affected.
| to_tsquery |
| 'busi' & 'analyt' |
#Search Dictionary
\dt pg_catalog.pg_language
> 1 rows affected.
| Schema |
Name |
Type |
Owner |
| pg_catalog |
pg_language |
table |
postgres |
SELECT plainto_tsquery('business analytics');
> 1 rows affected.
| plainto_tsquery |
| 'busi' & 'analyt' |
-- combine tsquery (|| or condition)
SELECT plainto_tsquery('business analyst') || phraseto_tsquery('data scientist');
> 1 rows affected.
| ?column? |
| 'busi' & 'analyst' | 'data' <-> 'scientist' |
-- failing since
-- SELECT "lazy dog and datascientist"::tsquery
SELECT
to_tsvector('english', 'a fat cat sat on a mat - it ate a fat rats') as to_tsvector
> 1 rows affected.
| to_tsvector |
| 'ate':9 'cat':3 'fat':2,11 'mat':7 'rat':12 'sat':4 |
-- add dataset
SELECT left(title, 50) as title, left(notes,120) as notes
FROM employees
WHERE notes @@ to_tsquery('sales & (served | degree)') AND title > ''
> 2 rows affected.
| title |
notes |
| Sales Representative |
Janet has a BS degree in chemistry from Boston College (1984). She has also completed a certificate program in food ret |
| Sales Manager |
Steven Buchanan graduated from St. Andrews University, Scotland, with a BSC degree in 1976. Upon joining the company as |
#Querying for Data
SELECT values_to_display
FROM table_anme
WHERE expression
GROUP BY how_to_group
HAVING expression
ORDER BY how_to_group
LIMIT row_limit;
SELECT product_id, product_name, quantity_per_unit, unit_price FROM "products" LIMIT 5
> 5 rows affected.
| product_id |
product_name |
quantity_per_unit |
unit_price |
| 1 |
Chai |
10 boxes x 30 bags |
18.0 |
| 2 |
Chang |
24 - 12 oz bottles |
19.0 |
| 3 |
Aniseed Syrup |
12 - 550 ml bottles |
10.0 |
| 4 |
Chef Anton's Cajun Seasoning |
48 - 6 oz jars |
22.0 |
| 5 |
Chef Anton's Gumbo Mix |
36 boxes |
21.35 |
Using math in SQL
+ - addition- - subtraction* - multiplier/ - division^ - power|/ - quadratic power
SELECT product_id, product_name, units_in_stock * unit_price as price FROM "products" LIMIT 5
> 5 rows affected.
| product_id |
product_name |
price |
| 1 |
Chai |
702.0 |
| 2 |
Chang |
323.0 |
| 3 |
Aniseed Syrup |
130.0 |
| 4 |
Chef Anton's Cajun Seasoning |
1166.0 |
| 5 |
Chef Anton's Gumbo Mix |
0.0 |
#DISTINCT
SELECT DISTINCT city FROM employees
> 5 rows affected.
| city |
| Redmond |
| London |
| Tacoma |
| Kirkland |
| Seattle |
SELECT DISTINCT city, country FROM employees
> 5 rows affected.
| city |
country |
| Seattle |
USA |
| Kirkland |
USA |
| London |
UK |
| Redmond |
USA |
| Tacoma |
USA |
#WHERE & OREDER BY
SELECT order_id, customer_id, order_date, shipped_date FROM orders WHERE ship_city = 'Oulu' LIMIT 5
> 5 rows affected.
| order_id |
customer_id |
order_date |
shipped_date |
| 10266 |
WARTH |
1996-07-26 |
1996-07-31 |
| 10270 |
WARTH |
1996-08-01 |
1996-08-02 |
| 10320 |
WARTH |
1996-10-03 |
1996-10-18 |
| 10333 |
WARTH |
1996-10-18 |
1996-10-25 |
| 10412 |
WARTH |
1997-01-13 |
1997-01-15 |
SELECT ship_country, ship_city, freight FROM orders WHERE ship_city != 'Oulu' AND freight > 30 ORDER BY freight DESC LIMIT 4
> 4 rows affected.
| ship_country |
ship_city |
freight |
| Germany |
Cunewalde |
1007.64 |
| Brazil |
Sao Paulo |
890.78 |
| USA |
Boise |
830.75 |
| Germany |
Cunewalde |
810.05 |
SELECT ship_country, ship_city, freight FROM orders WHERE ship_city <> 'Oulu' AND freight > 30 LIMIT 4
> 4 rows affected.
| ship_country |
ship_city |
freight |
| France |
Reims |
32.38 |
| Brazil |
Rio de Janeiro |
65.83 |
| France |
Lyon |
41.34 |
| Belgium |
Charleroi |
51.3 |
SELECT ship_country, ship_city, freight FROM orders WHERE order_date > '1998-04-10' LIMIT 4
> 4 rows affected.
| ship_country |
ship_city |
freight |
| Austria |
Graz |
754.26 |
| USA |
Portland |
11.65 |
| Argentina |
Buenos Aires |
3.17 |
| Germany |
Köln |
43.3 |
#AND, OR and NOT
SELECT customer_id, company_name, contact_name, contact_title, address, city
FROM customers
WHERE city = 'London' OR city = 'Berlin' LIMIT 4
> 4 rows affected.
| customer_id |
company_name |
contact_name |
contact_title |
address |
city |
| ALFKI |
Alfreds Futterkiste |
Maria Anders |
Sales Representative |
Obere Str. 57 |
Berlin |
| AROUT |
Around the Horn |
Thomas Hardy |
Sales Representative |
120 Hanover Sq. |
London |
| BSBEV |
B's Beverages |
Victoria Ashworth |
Sales Representative |
Fauntleroy Circus |
London |
| CONSH |
Consolidated Holdings |
Elizabeth Brown |
Sales Representative |
Berkeley Gardens 12 Brewery |
London |
SELECT product_id, product_name, supplier_id, category_id, quantity_per_unit, unit_price, units_in_stock
FROM products WHERE (units_in_stock < units_on_order ) OR ( discontinued = 1 ) LIMIT 4
> 4 rows affected.
| product_id |
product_name |
supplier_id |
category_id |
quantity_per_unit |
unit_price |
units_in_stock |
| 1 |
Chai |
8 |
1 |
10 boxes x 30 bags |
18.0 |
39 |
| 2 |
Chang |
1 |
1 |
24 - 12 oz bottles |
19.0 |
17 |
| 3 |
Aniseed Syrup |
1 |
2 |
12 - 550 ml bottles |
10.0 |
13 |
| 5 |
Chef Anton's Gumbo Mix |
2 |
2 |
36 boxes |
21.35 |
0 |
SELECT customer_id, company_name, contact_name, contact_title, address, city
FROM customers WHERE city = 'London' OR city = 'Berlin' LIMIT 4
> 4 rows affected.
| customer_id |
company_name |
contact_name |
contact_title |
address |
city |
| ALFKI |
Alfreds Futterkiste |
Maria Anders |
Sales Representative |
Obere Str. 57 |
Berlin |
| AROUT |
Around the Horn |
Thomas Hardy |
Sales Representative |
120 Hanover Sq. |
London |
| BSBEV |
B's Beverages |
Victoria Ashworth |
Sales Representative |
Fauntleroy Circus |
London |
| CONSH |
Consolidated Holdings |
Elizabeth Brown |
Sales Representative |
Berkeley Gardens 12 Brewery |
London |
SELECT customer_id, company_name, contact_name, contact_title, address, city
FROM customers WHERE city NOT IN ('London', 'Berlin') LIMIT 4
> 4 rows affected.
| customer_id |
company_name |
contact_name |
contact_title |
address |
city |
| ANATR |
Ana Trujillo Emparedados y helados |
Ana Trujillo |
Owner |
Avda. de la Constitución 2222 |
México D.F. |
| ANTON |
Antonio Moreno Taquería |
Antonio Moreno |
Owner |
Mataderos 2312 |
México D.F. |
| BERGS |
Berglunds snabbköp |
Christina Berglund |
Order Administrator |
Berguvsvägen 8 |
Luleå |
| BLAUS |
Blauer See Delikatessen |
Hanna Moos |
Sales Representative |
Forsterstr. 57 |
Mannheim |
#BETWEEN
SELECT * FROM (
SELECT o.customer_id, SUM(od.unit_price * od.quantity) as tot
FROM orders as o, order_details as od
WHERE od.order_id = o.order_id
GROUP BY o.customer_id
) as data
WHERE data.tot BETWEEN 5000 AND 6500 LIMIT 3
> 3 rows affected.
| customer_id |
tot |
| MORGK |
5042.200035095215 |
| BOLID |
5297.800024032593 |
| SANTG |
5735.1500153541565 |
#Agregate with MIN, MAX, SUM & AVG
SELECT MIN(order_date), MAX(order_date) FROM orders WHERE ship_city = 'London'
> 1 rows affected.
| min |
max |
| 1996-08-26 |
1998-04-29 |
SELECT AVG(unit_price) FROM products
> 1 rows affected.
SELECT SUM(units_in_stock*unit_price) as price FROM products
> 1 rows affected.
#Agregate with COUNT(*)
SELECT COUNT(DISTINCT ship_city) FROM orders
> 1 rows affected.
#Agregate Group Contcat
Alternative to GROUP_CONCAT
#CREATE AGGREGATE
mechanix changed in pg14
CREATE OR REPLACE FUNCTION _group_concat_finalize(anyarray)
RETURNS text AS $$
SELECT array_to_string($1,',')
$$ IMMUTABLE LANGUAGE SQL;
CREATE OR REPLACE AGGREGATE group_concat(anycompatible) (
SFUNC=array_append,
STYPE=anycompatiblearray,
FFUNC=_group_concat_finalize,
INITCOND='{}'
);
SELECT customer_id, group_concat(DISTINCT ship_city) FROM orders GROUP BY customer_id LIMIT 5;
> Done.
> Done.
> 5 rows affected.
| customer_id |
group_concat |
| ALFKI |
['Berlin'] |
| ANATR |
['México D.F.'] |
| ANTON |
['México D.F.'] |
| AROUT |
['Colchester'] |
| BERGS |
['Luleå'] |
#LIKE
Examples:
- LIKE “%john%” – contains john
- LIKE “john%” – start with john
- LIKE “%john” – ends on john
SELECT first_name, last_name FROM employees WHERE last_name LIKE '_avolio' OR last_name LIKE '%King%'
> 2 rows affected.
| first_name |
last_name |
| Nancy |
Davolio |
| Robert |
King |
#SIMILAR TO ~
SELECT customer_id, phone
FROM customers
WHERE phone ~
E'[(]{0,1}[0-9]{3}[)-.]{0,1}[\\s]{0,1}[0-9]{3}[-.]{0,1}[0-9]{4}'
LIMIT 4
> 0 rows affected.
#Dealing with NULL
SELECT ship_city, ship_region, ship_country FROM orders WHERE ship_region is NULL LIMIT 2
> 2 rows affected.
| ship_city |
ship_region |
ship_country |
| Reims |
None |
France |
| Münster |
None |
Germany |
SELECT ship_city, ship_region, ship_country FROM orders WHERE ship_region is NOT NULL LIMIT 2
> 2 rows affected.
| ship_city |
ship_region |
ship_country |
| Rio de Janeiro |
RJ |
Brazil |
| Rio de Janeiro |
RJ |
Brazil |
#GROUP BY
SELECT ship_country, count(*) FROM orders WHERE freight > 10 GROUP by ship_country ORDER BY count DESC LIMIT 5
> 5 rows affected.
| ship_country |
count |
| Germany |
104 |
| USA |
104 |
| Brazil |
62 |
| France |
55 |
| UK |
41 |
#TODO: WITH ROLLUP
#HAVING
Post selection group
SELECT * FROM (
SELECT o.customer_id, SUM(od.unit_price * od.quantity) as tot
FROM orders as o, order_details as od
WHERE od.order_id = o.order_id
GROUP BY o.customer_id
) as data
WHERE data.tot BETWEEN 5000 AND 6500
> 7 rows affected.
| customer_id |
tot |
| MORGK |
5042.200035095215 |
| BOLID |
5297.800024032593 |
| SANTG |
5735.1500153541565 |
| BSBEV |
6089.899990081787 |
| WELLI |
6480.69997215271 |
| PRINI |
5317.100019454956 |
| ISLAT |
6146.299984931946 |
SELECT o.customer_id, SUM(od.unit_price * od.quantity)
FROM orders as o, order_details as od
WHERE od.order_id = o.order_id
GROUP BY o.customer_id
HAVING SUM(od.unit_price * od.quantity) BETWEEN 5000 AND 6500
ORDER BY sum
> 7 rows affected.
| customer_id |
sum |
| MORGK |
5042.200035095215 |
| BOLID |
5297.800024032593 |
| PRINI |
5317.100019454956 |
| SANTG |
5735.1500153541565 |
| BSBEV |
6089.899990081787 |
| ISLAT |
6146.299984931946 |
| WELLI |
6480.69997215271 |
#UNION
The SQL UNION clause/operator is used to combine the results of two or more SELECT statements without returning any duplicate rows.
SELECT * FROM (
SELECT country FROM customers
UNION
SELECT country FROM employees
) as source LIMIT 2
> 2 rows affected.
Th UNION ALL command combines the result set of two or more SELECT statements (allows duplicate values).
-- do not remove duplicates
SELECT * FROM (
SELECT country FROM customers
UNION ALL
SELECT country FROM employees
) as source LIMIT 3
> 3 rows affected.
| country |
| Germany |
| Mexico |
| Mexico |
#INTERSECT
The SQL INTERSECT clause/operator is used to combine two SELECT statements, but returns rows only from the first SELECT statement that are identical to a row in the second SELECT statement. This means INTERSECT returns only common rows returned by the two SELECT statements.
SELECT * FROM (
SELECT country FROM customers
INTERSECT
SELECT country FROM employees
) as source LIMIT 2
> 2 rows affected.
#EXCEPT
The SQL EXCEPT clause/operator is used to combine two SELECT statements and returns rows from the first SELECT statement that are not returned by the second SELECT statement. This means EXCEPT returns only rows, which are not available in the second SELECT statement.
-- do not remove duplicates
SELECT * FROM (
SELECT country FROM customers
EXCEPT
SELECT country FROM employees
) as source LIMIT 2
> 2 rows affected.
-- do not remove duplicates
SELECT * FROM (
SELECT country FROM customers
EXCEPT ALL
SELECT country FROM employees
) as source LIMIT 2
> 2 rows affected.
#RETURNING
WARNING: Jupyter doesnt work correctly with returning *, so we are wrpapping it
# can't perform magic with returning *
try:
data = UPDATE employees SET title_of_courtesy = 'Mrs' WHERE employee_id = 1 RETURNING *
print(data)
except:
pass
> 1 rows affected.
UPDATE employees SET title_of_courtesy = 'Mrs' WHERE employee_id = 1 RETURNING title_of_courtesy, last_name
> 1 rows affected.
| title_of_courtesy |
last_name |
| Mrs |
Davolio |
UPDATE employees SET title_of_courtesy = 'Ms' WHERE employee_id = 1 RETURNING title_of_courtesy, last_name
> 1 rows affected.
| title_of_courtesy |
last_name |
| Ms |
Davolio |
INSERT INTO employees (employee_id, first_name, last_name)
VALUES (10, 'John', 'Dow')
RETURNING title_of_courtesy, first_name, last_name
> 1 rows affected.
| title_of_courtesy |
first_name |
last_name |
| None |
John |
Dow |
UPDATE employees SET title_of_courtesy = 'Dr' WHERE employee_id = 10 RETURNING title_of_courtesy, last_name
> 1 rows affected.
| title_of_courtesy |
last_name |
| Dr |
Dow |
DELETE FROM employees WHERE employee_id = 10 RETURNING title_of_courtesy, last_name, first_name
> 1 rows affected.
| title_of_courtesy |
last_name |
first_name |
| Dr |
Dow |
John |
#TODO Indexes
#SQL Expressions
SELECT VERSION()
> 1 rows affected.
| version |
| PostgreSQL 15.4 (Debian 15.4-2.pgdg120+1) on aarch64-unknown-linux-gnu, compiled by gcc (Debian 12.2.0-14) 12.2.0, 64-bit |
SELECT 1+2+4.0
> 1 rows affected.
SELECT 1+2+4.0 = 7
> 1 rows affected.
#TODO Updating Data
#Joins
#INNER JOIN
Only Common Values of two tables.

SELECT product_name, company_name, units_in_stock
FROM products p
INNER JOIN suppliers s ON (p.supplier_id = s.supplier_id )
LIMIT 5
> 5 rows affected.
| product_name |
company_name |
units_in_stock |
| Chai |
Specialty Biscuits, Ltd. |
39 |
| Chang |
Exotic Liquids |
17 |
| Aniseed Syrup |
Exotic Liquids |
13 |
| Chef Anton's Cajun Seasoning |
New Orleans Cajun Delights |
53 |
| Chef Anton's Gumbo Mix |
New Orleans Cajun Delights |
0 |
SELECT c.category_name, SUM(p.units_in_stock)
FROM products p
INNER JOIN categories c ON (p.category_id = c.category_id)
GROUP BY c.category_id
ORDER BY sum
> 8 rows affected.
| category_name |
sum |
| Produce |
100 |
| Meat/Poultry |
165 |
| Grains/Cereals |
308 |
| Confections |
386 |
| Dairy Products |
393 |
| Condiments |
507 |
| Beverages |
559 |
| Seafood |
701 |
SELECT c.category_name, SUM(p.units_in_stock * p.unit_price)
FROM products p
INNER JOIN categories c ON (p.category_id = c.category_id)
WHERE p.discontinued != 1
GROUP BY c.category_id
ORDER BY sum
LIMIT 4
> 4 rows affected.
| category_name |
sum |
| Produce |
2363.75 |
| Meat/Poultry |
2916.449995994568 |
| Grains/Cereals |
5230.5 |
| Confections |
10392.200072288513 |
SELECT order_date, product_name, ship_country, p.unit_price
FROM orders
INNER JOIN order_details as od ON (orders.order_id = od.order_id)
INNER JOIN products as p ON (od.product_id = p.product_id)
LIMIT 5
> 5 rows affected.
| order_date |
product_name |
ship_country |
unit_price |
| 1996-07-04 |
Queso Cabrales |
France |
21.0 |
| 1996-07-04 |
Singaporean Hokkien Fried Mee |
France |
14.0 |
| 1996-07-04 |
Mozzarella di Giovanni |
France |
34.8 |
| 1996-07-05 |
Tofu |
Germany |
23.25 |
| 1996-07-05 |
Manjimup Dried Apples |
Germany |
53.0 |
SELECT
order_date, product_name, ship_country, p.unit_price,
contact_name, company_name
FROM orders as o
JOIN order_details as od ON (o.order_id = od.order_id)
INNER JOIN products as p ON (od.product_id = p.product_id)
JOIN customers as c ON (o.customer_id = c.customer_id)
JOIN employees as e ON (o.employee_id = e.employee_id)
WHERE ship_country = 'USA'
LIMIT 5
> 5 rows affected.
| order_date |
product_name |
ship_country |
unit_price |
contact_name |
company_name |
| 1997-05-06 |
Queso Cabrales |
USA |
21.0 |
Howard Snyder |
Great Lakes Food Market |
| 1997-05-06 |
Geitost |
USA |
2.5 |
Howard Snyder |
Great Lakes Food Market |
| 1997-05-06 |
Mozzarella di Giovanni |
USA |
34.8 |
Howard Snyder |
Great Lakes Food Market |
| 1997-07-04 |
Steeleye Stout |
USA |
18.0 |
Howard Snyder |
Great Lakes Food Market |
| 1997-07-31 |
Côte de Blaye |
USA |
263.5 |
Howard Snyder |
Great Lakes Food Market |
#LEFT (OUTTER) JOIN
Only values of the the Left table and matches of the Right tables.
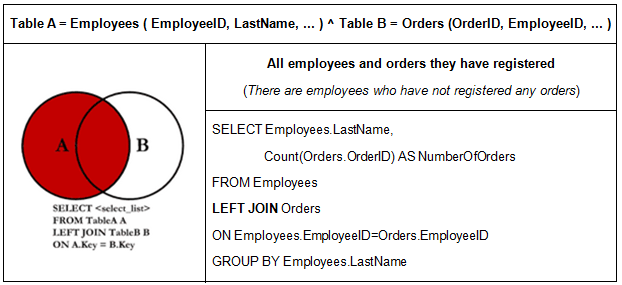
SELECT company_name as supplier, product_name as product
FROM suppliers as s
LEFT JOIN products as p ON (p.supplier_id = s.supplier_id )
LIMIT 3
> 3 rows affected.
| supplier |
product |
| Exotic Liquids |
Chang |
| Exotic Liquids |
Aniseed Syrup |
| New Orleans Cajun Delights |
Chef Anton's Cajun Seasoning |
#LEFT (OUTTER) JOIN *
Only values of the the Left table and not matches of the Right tables.

SELECT company_name as customer, c.customer_id
FROM customers as c
LEFT JOIN orders as o ON (o.customer_id = c.customer_id )
WHERE order_id is NULL
> 2 rows affected.
| customer |
customer_id |
| Paris spécialités |
PARIS |
| FISSA Fabrica Inter. Salchichas S.A. |
FISSA |
SELECT last_name, order_id
FROM employees as e
LEFT JOIN orders as o ON (o.employee_id = e.employee_id )
WHERE order_id is NULL
> 0 rows affected.
#RIGHT (OUTTER) JOIN
Only values of the the Right table and matches of the Left table.

SELECT company_name as supplier, product_name as product
FROM products as p
LEFT JOIN suppliers as s ON (p.supplier_id = s.supplier_id )
LIMIT 3
> 3 rows affected.
| supplier |
product |
| Specialty Biscuits, Ltd. |
Chai |
| Exotic Liquids |
Chang |
| Exotic Liquids |
Aniseed Syrup |
#RIGHT (OUTTER) JOIN *
Only values of the the Right table and not matches of the Left table.

-- same request that we did for left join.
SELECT company_name as customer, c.customer_id
FROM orders as o
RIGHT JOIN customers as c ON (o.customer_id = c.customer_id )
WHERE order_id is NULL
> 2 rows affected.
| customer |
customer_id |
| Paris spécialités |
PARIS |
| FISSA Fabrica Inter. Salchichas S.A. |
FISSA |
#FULL JOIN
All values from left and right (with nulls on non matching values)

SELECT company_name as customer, c.customer_id
FROM orders as o
FULL JOIN customers as c ON (o.customer_id = c.customer_id )
LIMIT 10
> 10 rows affected.
| customer |
customer_id |
| Vins et alcools Chevalier |
VINET |
| Toms Spezialitäten |
TOMSP |
| Hanari Carnes |
HANAR |
| Victuailles en stock |
VICTE |
| Suprêmes délices |
SUPRD |
| Hanari Carnes |
HANAR |
| Chop-suey Chinese |
CHOPS |
| Richter Supermarkt |
RICSU |
| Wellington Importadora |
WELLI |
| HILARION-Abastos |
HILAA |
#CROSS JOIN
All combinations of values from left and right

SELECT count(*)
FROM orders as o
CROSS JOIN customers as c
> 1 rows affected.
#SELF JOIN
CREATE TABLE IF NOT EXISTS extras_self_join_example (
id INT PRIMARY KEY,
name VARCHAR(255) NOT NULL,
pid INT,
FOREIGN KEY (pid) REFERENCES extras_self_join_example (id)
);
> Done.
result >>> []
INSERT INTO extras_self_join_example (
id, name, pid
) VALUES
(1, 'Foo', NULL),
(2, 'Bar', 1),
(3, 'Baz', 2),
(4, 'Quz', 1);
> 4 rows affected.
result >>> []
SELECT e.name || '/' || e2.name, e2.pid
FROM extras_self_join_example as e
LEFT JOIN extras_self_join_example as e2 ON e2.pid = e.id
WHERE e2.pid IS NOT NULL
ORDER BY e2.pid DESC
> 3 rows affected.
| ?column? |
pid |
| Bar/Baz |
2 |
| Foo/Bar |
1 |
| Foo/Quz |
1 |
DROP TABLE extras_self_join_example
> Done.
result >>> []
#USING keyword
Allows to use shared column to make join
SELECT product_name, company_name, units_in_stock
FROM products p
INNER JOIN suppliers USING(supplier_id)
LIMIT 5
> 5 rows affected.
| product_name |
company_name |
units_in_stock |
| Chai |
Specialty Biscuits, Ltd. |
39 |
| Chang |
Exotic Liquids |
17 |
| Aniseed Syrup |
Exotic Liquids |
13 |
| Chef Anton's Cajun Seasoning |
New Orleans Cajun Delights |
53 |
| Chef Anton's Gumbo Mix |
New Orleans Cajun Delights |
0 |
#NATURAL JOIN
Joining tables using columns with same name
SELECT product_name, company_name, units_in_stock
FROM products p
NATURAL JOIN suppliers
LIMIT 5
> 5 rows affected.
| product_name |
company_name |
units_in_stock |
| Chai |
Specialty Biscuits, Ltd. |
39 |
| Chang |
Exotic Liquids |
17 |
| Aniseed Syrup |
Exotic Liquids |
13 |
| Chef Anton's Cajun Seasoning |
New Orleans Cajun Delights |
53 |
| Chef Anton's Gumbo Mix |
New Orleans Cajun Delights |
0 |
#SubQueries
SELECT company_name, country
FROM suppliers as s
WHERE s.country IN (
SELECT DISTINCT(country) FROM customers
)
ORDER BY s.company_name
LIMIT 4
> 4 rows affected.
| company_name |
country |
| Aux joyeux ecclésiastiques |
France |
| Bigfoot Breweries |
USA |
| Cooperativa de Quesos 'Las Cabras' |
Spain |
| Escargots Nouveaux |
France |
SELECT DISTINCT(s.company_name), country
FROM suppliers as s
JOIN customers as c USING(country)
ORDER BY s.company_name
LIMIT 4
> 4 rows affected.
| company_name |
country |
| Aux joyeux ecclésiastiques |
France |
| Bigfoot Breweries |
USA |
| Cooperativa de Quesos 'Las Cabras' |
Spain |
| Escargots Nouveaux |
France |
SELECT category_name, SUM(units_in_stock)
FROM products
INNER JOIN categories USING(category_id)
GROUP BY category_name
ORDER BY sum desc
LIMIT (SELECT MIN(product_id)+4 FROM PRODUCTS)
> 5 rows affected.
| category_name |
sum |
| Seafood |
701 |
| Beverages |
559 |
| Condiments |
507 |
| Dairy Products |
393 |
| Confections |
386 |
SELECT product_name, units_in_stock
FROM products
WHERE units_in_stock > (SELECT AVG(units_in_stock) FROM products)
ORDER BY units_in_stock DESC
LIMIT 5
> 5 rows affected.
| product_name |
units_in_stock |
| Rhönbräu Klosterbier |
125 |
| Boston Crab Meat |
123 |
| Grandma's Boysenberry Spread |
120 |
| Pâté chinois |
115 |
| Sirop d'érable |
113 |
#EXISTS
-- join like experience
SELECT company_name, contact_name
FROM customers
WHERE EXISTS (
SELECT customer_id FROM orders WHERE customer_id = customers.customer_id and freight > 800
)
> 3 rows affected.
| company_name |
contact_name |
| Queen Cozinha |
Lúcia Carvalho |
| QUICK-Stop |
Horst Kloss |
| Save-a-lot Markets |
Jose Pavarotti |
SELECT c.company_name, c.contact_name, o.freight
FROM customers as c
INNER JOIN orders as o ON (o.customer_id = c.customer_id and o.freight > 800)
> 4 rows affected.
| company_name |
contact_name |
freight |
| Queen Cozinha |
Lúcia Carvalho |
890.78 |
| QUICK-Stop |
Horst Kloss |
1007.64 |
| QUICK-Stop |
Horst Kloss |
810.05 |
| Save-a-lot Markets |
Jose Pavarotti |
830.75 |
#ANY
SELECT DISTINCT(company_name)
FROM customers
JOIN orders USING (customer_id)
JOIN order_details USING (order_id)
WHERE quantity > 100
> 3 rows affected.
| company_name |
| Ernst Handel |
| Save-a-lot Markets |
| QUICK-Stop |
SELECT DISTINCT(company_name)
FROM customers
WHERE customer_id = ANY(SELECT customer_id FROM orders JOIN order_details USING(order_id) WHERE quantity > 100)
> 3 rows affected.
| company_name |
| Ernst Handel |
| Save-a-lot Markets |
| QUICK-Stop |
SELECT DISTINCT p.product_name, od.quantity
FROM products as p
JOIN order_details as od USING(product_id)
WHERE od.quantity > (SELECT AVG(quantity) from order_details)
ORDER BY quantity
LIMIT 3
> 3 rows affected.
| product_name |
quantity |
| Jack's New England Clam Chowder |
24 |
| Chef Anton's Cajun Seasoning |
24 |
| Pavlova |
24 |
#Views
CREATE VIEW view_products_of_suppliers as
SELECT product_name, company_name, units_in_stock
FROM products p
INNER JOIN suppliers s ON (p.supplier_id = s.supplier_id )
> Done.
result >>> []
SELECT * FROM view_products_of_suppliers LIMIT 5
> 5 rows affected.
| product_name |
company_name |
units_in_stock |
| Chai |
Specialty Biscuits, Ltd. |
39 |
| Chang |
Exotic Liquids |
17 |
| Aniseed Syrup |
Exotic Liquids |
13 |
| Chef Anton's Cajun Seasoning |
New Orleans Cajun Delights |
53 |
| Chef Anton's Gumbo Mix |
New Orleans Cajun Delights |
0 |
#Droping Views
DROP VIEW view_products_of_suppliers;
> Done.
result >>> []
#Create Or Replace Views
CREATE OR REPLACE VIEW view_products_of_suppliers as
SELECT company_name, product_name, units_in_stock
FROM products p
INNER JOIN suppliers s ON (p.supplier_id = s.supplier_id )
> Done.
result >>> []
https://www.postgresql.org/docs/13/sql-alterview.html
ALTER VIEW IF EXISTS view_products_of_suppliers
RENAME TO products_of_suppliers_relation;
> Done.
result >>> []
#Inserting Into the Views
DROP VIEW IF EXISTS "empl_mrs";
CREATE VIEW "empl_mrs" as SELECT * FROM employees WHERE title_of_courtesy = 'Mrs'
> Done.
> Done.
result >>> []
INSERT INTO employees (employee_id, first_name, last_name, title_of_courtesy)
VALUES (12, 'Johnna', 'Dow', 'Ms')
RETURNING title_of_courtesy, first_name, last_name
> 1 rows affected.
| title_of_courtesy |
first_name |
last_name |
| Ms |
Johnna |
Dow |
#TODO: Adding checks to prevent bypassing filters
- WITH LOCAL CHECK OPTION;
- WITH CASCADE CHECK OPTION;
#TODO Importing and Exporting data
#TODO User Variables
#TODO Prepared Statements
#Stored Procedures and Functions
#Procedures
DROP PROCEDURE IF EXISTS test_proc();
CREATE PROCEDURE test_proc()
as $$
BEGIN
CREATE TABLE IF NOT EXISTS a (aid int);
CREATE TABLE IF NOT EXISTS b (bid int);
COMMIT;
CREATE TABLE IF NOT EXISTS c (cid int);
ROLLBACK;
END;
$$ LANGUAGE plpgsql;
> Done.
> Done.
result >>> []
CALL test_proc();
> (psycopg2.errors.InvalidTransactionTermination) invalid transaction termination
> CONTEXT: PL/pgSQL function test_proc() line 5 at COMMIT
>
> [SQL: CALL test_proc();]
> (Background on this error at: https://sqlalche.me/e/20/2j85)
DROP table IF EXISTS a;
DROP table IF EXISTS b;
DROP table IF EXISTS c;
> Done.
> Done.
> Done.
result >>> []
#Functions: SQL
Selecting data from table
CREATE OR REPLACE FUNCTION get_product_price_by_name(name varchar) RETURNS real as $$
SELECT unit_price FROM products WHERE product_name = name
$$ LANGUAGE SQL;
SELECT * FROM get_product_price_by_name('Tofu')
> Done.
> 1 rows affected.
| get_product_price_by_name |
| 23.25 |
CREATE OR REPLACE FUNCTION get_total_number_of_goods() RETURNS bigint as $$
SELECT sum(units_in_stock) FROM products
$$ LANGUAGE sql;
SELECT get_total_number_of_goods();
> Done.
> 1 rows affected.
| get_total_number_of_goods |
| 3119 |
#OUT parameters
CREATE OR REPLACE FUNCTION get_product_priceboundaries(OUT max_price real, OUT min_price real) as $$
SELECT MAX(unit_price), MIN(unit_price) FROM products
$$ LANGUAGE SQL;
> Done.
result >>> []
SELECT get_product_priceboundaries()
> 1 rows affected.
| get_product_priceboundaries |
| (263.5,2.5) |
SELECT * FROM get_product_priceboundaries()
> 1 rows affected.
| max_price |
min_price |
| 263.5 |
2.5 |
SELECT min_price, max_price FROM get_product_priceboundaries()
> 1 rows affected.
| min_price |
max_price |
| 2.5 |
263.5 |
#DEFAULT parameters
CREATE OR REPLACE FUNCTION get_product_price_boundaries_by_discontinueity(
IN is_discontinued INT DEFAULT 0,
OUT max_price real,
OUT min_price real
) as $$
SELECT MAX(unit_price), MIN(unit_price) FROM products
WHERE discontinued = is_discontinued
$$ LANGUAGE SQL;
> Done.
result >>> []
SELECT * FROM get_product_price_boundaries_by_discontinueity()
> 1 rows affected.
| max_price |
min_price |
| 263.5 |
2.5 |
SELECT * FROM get_product_price_boundaries_by_discontinueity(0)
> 1 rows affected.
| max_price |
min_price |
| 263.5 |
2.5 |
SELECT * FROM get_product_price_boundaries_by_discontinueity(1)
> 1 rows affected.
| max_price |
min_price |
| 123.79 |
4.5 |
#DECLARE Variables
CREATE OR REPLACE FUNCTION get_triangle_square(a real, b real, c real) RETURNS real as $$
-- p for perimeter
DECLARE p real;
BEGIN
p = (a+b+c) / 2;
return sqrt(p) * (p-a) * (p-b) * (p-c);
END;
$$ LANGUAGE plpgsql;
> Done.
result >>> []
SELECT get_triangle_square(6,6,6)
> 1 rows affected.
#TODO IF/ELSEIF
#SETOF [table]
CREATE OR REPLACE FUNCTION get_price_in_range() RETURNS SETOF products as $$
DECLARE
avg_price real;
max_price real;
BEGIN
SELECT avg(unit_price)
INTO avg_price
FROM products;
-- in case if need somewhere else
max_price = avg_price * 1.05 ;
RETURN QUERY
SELECT * FROM products
WHERE unit_price BETWEEN (avg_price * 0.95) and max_price;
END;
$$ LANGUAGE plpgsql;
SELECT product_id, product_name FROM get_price_in_range();
> Done.
> 2 rows affected.
| product_id |
product_name |
| 7 |
Uncle Bob's Organic Dried Pears |
| 61 |
Sirop d'érable |
#RETURN NEXT
CREATE OR REPLACE FUNCTION return_ints() RETURNS SETOF int as $$
BEGIN
RETURN NEXT 1;
RETURN NEXT 3;
RETURN NEXT 2;
END
$$ LANGUAGE plpgsql;
SELECT return_ints();
> Done.
> 3 rows affected.
#Quick Proofing
DROP TABLE IF EXISTS tmp_customers;
SELECT * INTO tmp_customers FROM customers;
CREATE OR REPLACE FUNCTION update_null_region_in_customers() RETURNS void as $$
UPDATE tmp_customers SET region = 'unknown' WHERE region is NULL
$$ LANGUAGE SQL;
SELECT update_null_region_in_customers();
> Done.
> 91 rows affected.
> Done.
> 1 rows affected.
| update_null_region_in_customers |
| None |
#Counter
DO $$
BEGIN
FOR counter IN 1...10 BY 2
LOOP
RAISE NOTICE 'counter:... %', counter;
END LOOP;
END$$
> Done.
result >>> []
#Built-in Functions
#regexp_matches
SELECT regexp_matches ('<user2@mail.de,user3@mail.de>', '\w[\w.+-]*@[\w.-]+\.[\w-]{2,63}', 'g');
> 0 rows affected.
#NULLIF(a,b) - returns NULL if a == b
SELECT NULLIF('foo', 'bar'), NULLIF('foo', 'foo'), NULLIF(1, 0)
> 1 rows affected.
| nullif |
nullif_1 |
nullif_2 |
| foo |
None |
1 |
#COALESCE(a,b) - prefer b if a == null
SELECT COALESCE (Null, 'var'), COALESCE ('foo', 'bar')
> 1 rows affected.
| coalesce |
coalesce_1 |
| var |
foo |
#CASE … END - if else blocks
SELECT
order_id,
customer_id,
quantity,
CASE
WHEN quantity >= 100 THEN 'a lot'
WHEN quantity >= 40 THEN 'average'
WHEN quantity >= 20 THEN 'normal amount'
ELSE 'too few'
END as how_much
FROM orders
INNER JOIN order_details USING(order_id)
WHERE quantity > 10
and order_id in (11072, 10571)
ORDER BY how_much
LIMIT 10
> 5 rows affected.
| order_id |
customer_id |
quantity |
how_much |
| 11072 |
ERNSH |
130 |
a lot |
| 11072 |
ERNSH |
40 |
average |
| 10571 |
ERNSH |
28 |
normal amount |
| 11072 |
ERNSH |
22 |
normal amount |
| 10571 |
ERNSH |
11 |
too few |